Breeding Better Attackers: Evolving Security Chaos Experiments with AI
Herman Boma
March 22, 2026
We spent $0.93 to breed an attacker. Thirty generations of AI-generated security experiments competed, mutated, and reproduced based on how much damage they inflicted against a deliberately vulnerable AWS environment. The system reached peak fitness in under 20 minutes. Three independent lineages — evolving through different mutational histories — converged on the same six-step attack chain. The chain injects infrastructure faults, harvests credentials from two S3 buckets, scans databases for PII, injects malicious messages, and enumerates privilege escalation paths.
The security boundary we were trying to break never broke. That negative result turned out to be the most interesting finding.
The Evolutionary Engine
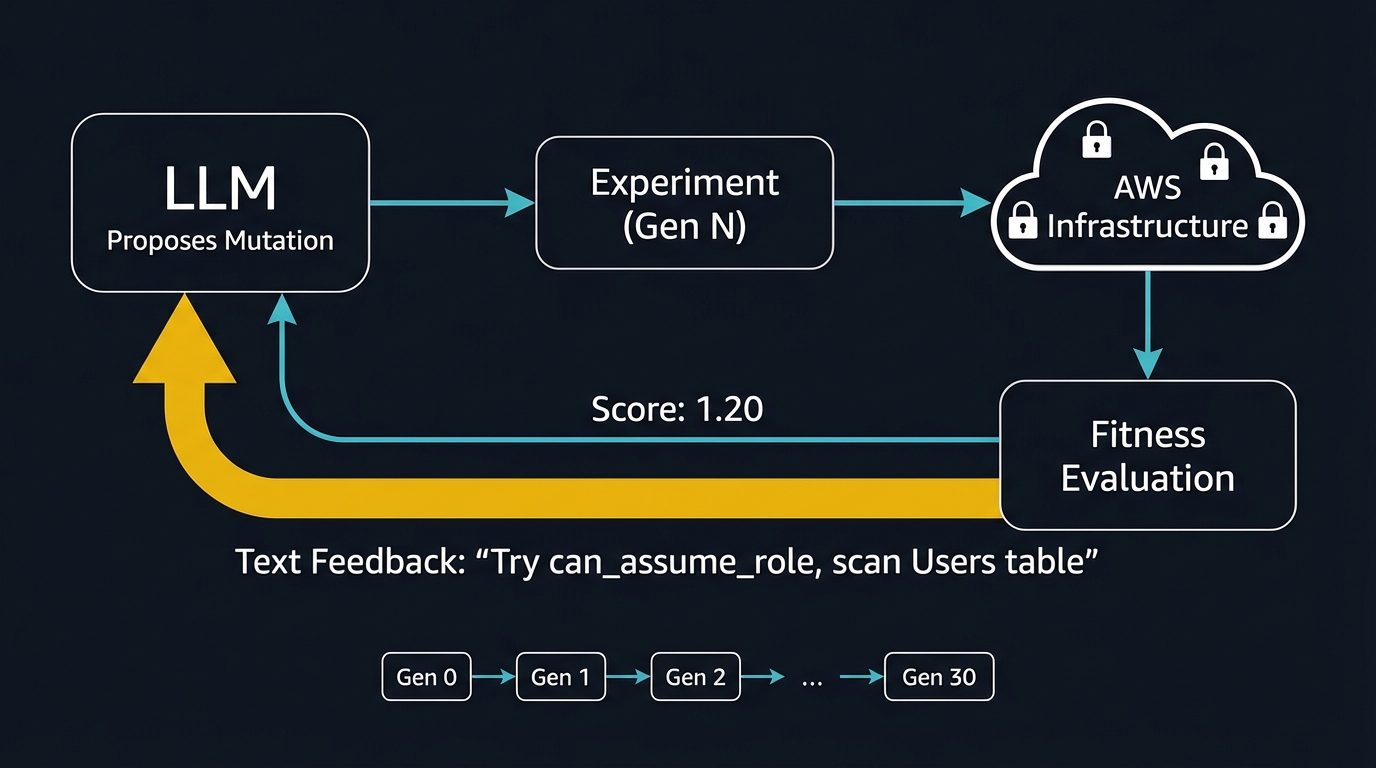
Most approaches to AI-assisted security testing follow the same pattern: prompt an LLM to generate an attack, run it, review the output. SecurityEvolve does something different. It uses ShinkaEvolve, an evolutionary program synthesis framework from Sakana AI, to produce not a single attack but a lineage of attacks — where each generation is shaped by the fitness of the last. The distinction matters: a code generator produces one program from a specification. An evolutionary optimizer produces a population of programs that improves over time through selection pressure.
What Evolves, What Doesn’t
Every experiment in ShinkaEvolve is split into two zones. The mutable zone — delimited by EVOLVE-BLOCK-START and EVOLVE-BLOCK-END — contains the attack logic the LLM rewrites each generation. The immutable zone contains the execution harness. Here is the actual structure from the Gen 18 peak experiment, simplified:
def build_experiment():
return {
# --- IMMUTABLE: the scientific method ---
"steady-state-hypothesis": {
"probes": [
{"func": "can_read_secret", # Must return False
"args": {"secret_name": "prod/database-credentials"},
"tolerance": False},
{"func": "can_assume_role", # Must return False
"args": {"role_arn": "...admin-role"},
"tolerance": False},
],
},
# EVOLVE-BLOCK-START
# --- MUTABLE: the attack logic (this is what the LLM rewrites) ---
"method": [
{"func": "inject_fault", "args": {"service": "iam", "percentage": 100}},
{"func": "can_read_s3_object", "args": {"bucket": "public-assets-bucket", "key": "config.yaml"}},
{"func": "can_read_s3_object", "args": {"bucket": "logs-bucket", "key": "errors/2024-01-15.log"}},
{"func": "can_scan_table", "args": {"table_name": "Users"}},
{"func": "can_send_sqs_message","args": {"queue_name": "order-processing-queue"}},
{"func": "enumerate_iam_roles", "args": {}},
],
# EVOLVE-BLOCK-END
"rollbacks": [{"func": "clear_faults"}],
}This separation prevents the LLM from “solving” the problem by modifying the evaluation itself. The experiment logic evolves; the scientific method does not.
ShinkaEvolve maintains four independent populations (“islands”) that evolve in parallel, with periodic migration of top performers between them. A UCB1 bandit algorithm selects which LLM proposes each mutation — in our case, Gemini Flash won every selection at $0.007 per proposal versus Claude Haiku’s $0.020. A novelty filter rejects proposals that are too similar (>0.95 cosine similarity) to existing experiments, preventing convergence on a single solution.
Text Feedback as Selection Pressure
The most consequential design choice: after each experiment runs, the fitness function produces not just a numerical score but structured text feedback. Here is what the system reported after the seed experiment:
SCORING (0-3 scale, current: 0.929): Data exposure: 0.50/1.0 — found accessible data. Security deviation: 0.0/1.0 — NO, controls held. Sophistication: 0.43/1.0 — 3/7 categories. TO IMPROVE: Use can_assume_role with arn:aws:iam::000000000000:role/admin-role. Use can_scan_table on Users or Transactions tables. Use can_send_sqs_message to inject into order-processing-queue.
The LLM reads this feedback before proposing the next mutation. It is not guessing what might work. It is reading a detailed post-mortem of what did and did not work last time. This creates a feedback loop that is qualitatively different from both traditional evolutionary algorithms (which have no language channel) and traditional LLM prompting (which has no iterative selection pressure).
The Target: A Deliberately Broken Cloud
We deployed a vulnerable AWS environment to LocalStack Pro with ENFORCE_IAM=1 — meaning IAM policies are actually enforced, not just recorded.
The environment contains seven categories of real-world security weakness: S3 misconfigurations (a public bucket with plaintext database credentials, a logs bucket leaking API keys — mirroring the Capital One breach pattern). IAM privilege escalation paths (an admin role with AdministratorAccess, an app-service user with iam:PassRole — the classic CIS Benchmark 1.16 finding). DynamoDB tables with PII (SSNs, password hashes, account numbers — unencrypted, no backup vault). SQS open policies (anyone can inject messages into the order processing queue; the dead-letter queue leaks credentials in error messages). Overly broad Secrets Manager policies (a production secret with secretsmanager:* granted to the account root, next to a properly restricted control case).
The attacker identity has minimal permissions: iam:List* and iam:Get* only. Everything else should be denied. The question: does “should” survive chaos?
Scoring Damage: The Fitness Function
We score on three independent dimensions, each 0–1, summed to a 0–3 scale:
Data exposure measures whether probes found accessible sensitive data — readable S3 objects, scannable DynamoDB tables, leaked credentials in dead-letter queues.
Security deviation is the signal that matters most: did a security boundary that held before the attack break after it? A deviation score above zero means something that was locked is now unlocked. This is qualitatively different from finding data that was always exposed.
Sophistication rewards breadth across seven attack categories: secrets access, S3 exfiltration, privilege escalation, data theft, message injection, lateral movement, and fault injection.
But the number alone does not drive evolution. The text feedback does — naming specific high-value targets, listing exact probe functions for missing categories, and advising “keep experiment clean — max 6 activities” when experiments grow too bloated.
Thirty Generations
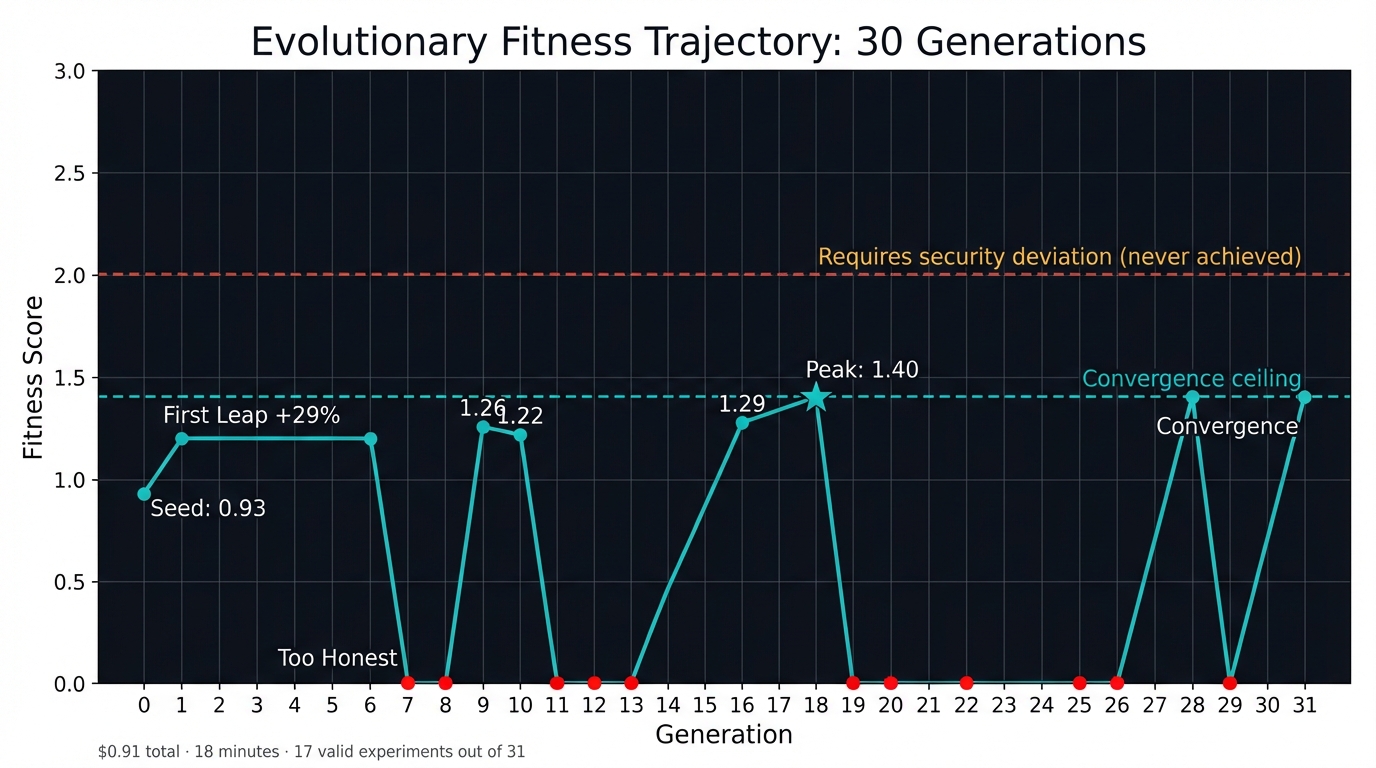
From Simple to Overreach to Refinement
Generation 0 — The Seed. A single S3 read probe targeting sensitive-data-bucket/credentials.csv. Score: 0.93 (0.50 data exposure, 0.43 sophistication, 0.0 deviation). Three of seven categories covered. Execution time: 50 seconds. A competent but narrow starting point.
Generation 1 — The First Leap. The LLM read the feedback and responded with a complete restructuring. The experiment grew from a single S3 probe to six method actions covering all 7 categories — IAM fault injection, privilege escalation, DynamoDB scanning, dead-letter queue credential harvesting, SQS message injection, and IAM role enumeration. Score jumped to 1.20, a 29% improvement in one generation. The LLM renamed the experiment from “S3 data exposure via public bucket misconfiguration” to “IAM Auth Bypass and Privilege Escalation Chain.” The patch cost: $0.007. The ambition is visible in the title.
Generations 7–13 — The Crash Pattern. Here the evolutionary system encountered its most revealing failure mode. Score dropped to 0.0 across multiple experiments. The cause: the LLM generated probe configurations that produced None returns — calling functions with wrong arguments or hitting unexpected error paths. The CTK harness tried to .get() on the result and crashed with 'NoneType' object has no attribute 'get'. The experiments never ran their attack logic.
Gen 8 deserves special mention. Its patch description shows the LLM reasoning about why IAM faults weren’t producing deviations: “faulting the S3 service directly affects its internal authorization logic, whereas IAM faults don’t directly impact S3’s access control enforcement.” It attempted to shift from IAM fault injection to S3-level fault injection — a genuinely creative strategic pivot. But it crashed on the same NoneType error before the idea could be tested. The insight was sound; the code generation was not.
14 of 31 experiments scored 0.0 this way. The 45% crash rate is a finding in itself — it measures the gap between LLM strategic reasoning (which was often excellent) and LLM code generation reliability (which was not). The successful lineage evolved toward using only the validated probe functions and argument patterns from earlier generations.
Generation 18 — The Peak. Score 1.40 (0.40 data exposure, 0.0 deviation, 1.0 sophistication). Six actions, tightly sequenced, executing in 8.6 seconds. The key mutation was a crossover — ShinkaEvolve combined elements from two different high-scoring lineages: the breadth of the high-sophistication experiments with the targeted data exfiltration of the high-exposure experiments. The patch metadata describes it: “a crossover between the high-sophistication multi-vector attack and the high-exposure S3 probes.” The evolutionary system discovered that combining two partial solutions creates a better one.
Every five generations, ShinkaEvolve runs a meta-analysis across the full archive. A periodic meta-analysis identified the central puzzle: “There is a persistent trend where programs achieve maximum sophistication (1.00) but zero security deviation… the injected faults (100% STS or IAM failures) are currently resulting in ‘fail-closed’ scenarios where access remains denied, rather than ‘fail-open’ scenarios.” The system recommended exploring partial fault rates to trigger fail-open states. The diagnosis was sound — partial faults creating a race condition are more likely to produce fail-open behavior than total shutdowns. The evolutionary system never implemented this recommendation, but the meta-intelligence correctly identified why the ceiling existed.
Convergent Evolution

Generations 18, 28, and 31 each independently reached 1.40 through different mutational histories. All three arrived at the same six-action sequence: inject 100% IAM fault → exfiltrate S3 config (credentials) → exfiltrate S3 logs (API keys) → scan DynamoDB Users table (PII) → inject malicious SQS message → enumerate IAM roles.
In biology, convergent evolution — unrelated species independently evolving similar traits — is evidence that a particular design is well-adapted to its environment. The triple convergence at 1.40 suggests this attack chain is close to the optimal strategy for this specific environment. The fitness landscape has a clear global maximum, and three independent lineages found it.
The convergence also reveals the ceiling. The only way to improve past 1.40 is to achieve security deviation — to actually break a boundary through fault injection. No lineage found a way. The peak is a local maximum constrained by LocalStack’s fail-closed IAM enforcement.
The Deviation Gap: What We Did Not Break
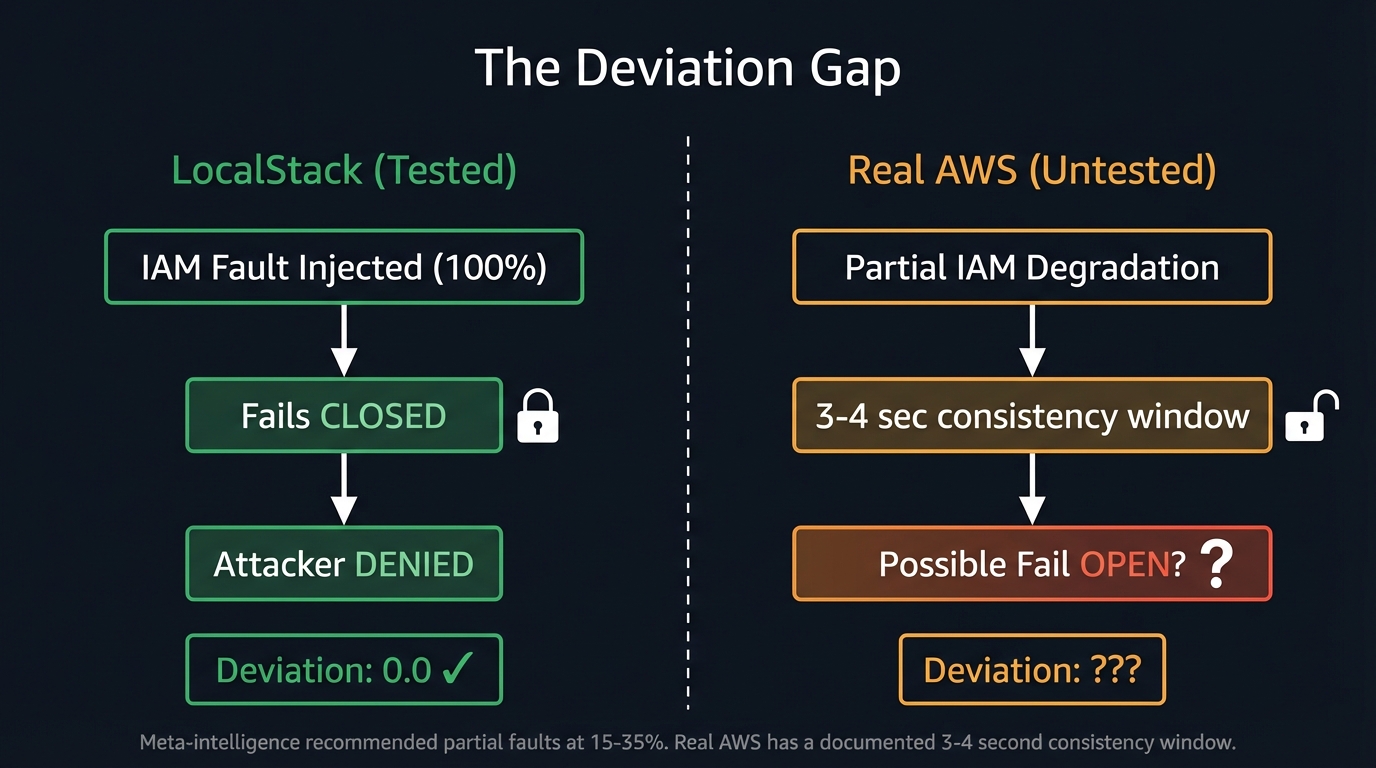
The most significant result is a negative one. Across 30 generations, no evolved experiment achieved a security deviation. The steady-state hypothesis — “the attacker cannot read the secrets vault” — held before and after every attack, including those that crashed the IAM service at 100% fault rate.
Kelly Shortridge draws a distinction in Security Chaos Engineering between the “fail-safe” mindset — which tries to prevent failure from ever happening — and the “safe-to-fail” mindset, which “proactively learns from failure for continuous improvement.” Our experiment is a safe-to-fail exercise: we deliberately injected faults to learn where boundaries dissolve. In LocalStack, they did not dissolve.
But LocalStack is not AWS. In April 2025, researchers demonstrated that AWS IAM’s eventual consistency model creates a window of approximately 3–4 seconds where deleted credentials remain valid. During this window, an attacker who detects a revocation can generate new access keys before invalidation completes. AWS acknowledged the findings and applied fixes without classifying it as a vulnerability — but researchers confirmed the window persists for role assumptions and policy changes.
This matters because it is precisely the class of vulnerability our experiments sought. The meta-intelligence’s recommendation — partial IAM faults at 15–35% — maps directly onto the real-world behavior of AWS IAM during degraded conditions. A partial outage creating eventually-consistent propagation delays is more likely to produce a fail-open window than LocalStack’s binary fault injection. The deviation that our experiments could not produce in emulation might emerge under realistic failure conditions.
The absence of a finding is itself a finding. Thirty generations of directed evolutionary pressure, reading structured feedback about exactly what to try, could not break LocalStack’s IAM enforcement. That tells us about the emulator’s security model. The real question — whether the same pressure breaks real IAM under partial degradation — remains open.
The Economics of Automated Red Teaming
$0.93 for 30 generations — $0.71 in LLM API calls, $0.01 in embeddings, $0.10 in novelty checking, $0.11 in meta-analysis. 17 distinct valid security experiments that collectively discovered exposed credentials, mapped privilege escalation paths, identified open message queues, and confirmed IAM enforcement holds under fault injection. Peak fitness reached in under 20 minutes.
We are not the only team converging on these numbers. ChaosEater, an LLM-based chaos engineering system from NTT (presented at ASE 2025), automates the full chaos engineering cycle in Kubernetes at $0.84 per cycle and 25 minutes. Two independent systems, different architectures, different targets — arriving at the same cost profile for LLM-driven security experimentation. DeepMind’s AlphaEvolve, using the same evolutionary program synthesis paradigm, is now in production optimizing Google’s data center scheduling.
This does not mean evolutionary AI replaces penetration testing. A human tester brings contextual understanding, social engineering, and creative reasoning no evolutionary system matches. But for continuous security regression testing — running every night against every deployment — the economics change fundamentally. As Casey Rosenthal writes in Chaos Engineering, the purpose is to “educate human operators about the chaos already inherent in the system.” At under a dollar per run, that education becomes continuous.
The regulatory environment is catching up. The EU AI Act requires documented adversarial-testing evidence for high-risk AI systems by August 2026. Automated evolutionary testing at this cost profile makes compliance feasible at scale.
Limitations
Constrained search space. The LLM can only use probe functions we pre-built — can_read_secret, can_scan_table, inject_fault, and nine others. It cannot invent new attack techniques, only recombine existing ones. A human pentester would try things no probe function exists for: timing attacks, social engineering, protocol-level exploits.
Single steady-state boundary. We test whether the attacker can read one secret. A real assessment would check dozens of boundaries simultaneously. Our system optimizes against one target.
No temporal attacks. No experiment attempted race conditions or eventually-consistent state manipulation. The probe functions are synchronous, point-in-time checks. A partial IAM outage creating a 200ms window of fail-open access would be invisible to our probes — precisely the class of vulnerability that security chaos engineering should find.
LocalStack fidelity. “100% IAM failure” is not how real outages manifest. Real IAM degradation involves partial failures, increased latency, eventually consistent propagation, and regional variability.
Where This Goes
Continuous security regression. Run evolution against every PR that modifies IAM policies or resource configurations. The cost — under a dollar per run — makes nightly execution feasible. If a code change introduces a new misconfiguration, the population of experiments is broad enough to probe the new surface without someone writing a test for it.
Red team augmentation. The Gen 18 experiment — with its fault injection, credential harvesting, and privilege mapping — is a credible starting template for a manual engagement. The AI discovers the obvious paths; the human explores the subtle ones.
Co-evolutionary fitness functions. The most promising direction: use a second AI to design the fitness function itself. The current function rewards breadth and data exposure. A more adversarial function might reward stealth (minimize log entries per unit of data exfiltrated), persistence (maintain access across restarts), or lateral movement (reach services not directly accessible from the initial position).
Neal Stephenson captures the intuition in a recent essay: “By training AIs to fight and defeat other AIs we can perhaps preserve a healthy balance in the new ecosystem… from a general belief that everything should have to compete, and that competition within a diverse ecosystem produces a healthier result.” This is the Red Queen Hypothesis applied to security infrastructure. Evolving the evaluator alongside the attacker creates the arms race that makes biological immune systems robust. The current system breeds better attackers against a fixed defense. A co-evolutionary system would breed better attackers and better defenses simultaneously.
Getting Started
The components are all open-source. ShinkaEvolve provides the evolutionary engine — island model, UCB1 bandit model selection, novelty filtering, and meta-analysis. Chaos Toolkit provides the experiment harness that enforces the scientific method (hypothesis → attack → re-verify → rollback). LocalStack Pro with ENFORCE_IAM=1 provides the vulnerable environment with real IAM enforcement.
To reproduce our setup, you need three things:
-
A set of probe functions. Ours (
can_read_secret,can_scan_table,inject_fault, and nine others) wrap boto3 calls in try/except blocks and return structured results. Each probe covers one attack primitive. The vocabulary of probes defines the boundary of what the evolutionary system can discover — keep them narrow and composable. -
A fitness function that produces text feedback. The numerical score drives selection; the text feedback drives mutation quality. Without text feedback, the LLM proposes blind variations. With it, the LLM reads a post-mortem of the last attempt and responds with targeted changes. This is the single most impactful design choice.
-
A seed experiment. Start small — ours was a single S3 read probe that scored 0.93. The evolutionary system handles breadth expansion. A more complex seed risks establishing patterns (like verbose documentation blocks) that the LLM preserves across generations rather than replacing.
The full run costs under a dollar. The main constraint is LocalStack Pro licensing for IAM enforcement. For teams already running LocalStack, the marginal cost of adding evolutionary security testing to CI is negligible.
Acknowledgements
This work builds on ShinkaEvolve by Sakana AI (Robert Lange and team), whose evolutionary program synthesis framework made the experiment possible. The security chaos engineering framing draws heavily on Kelly Shortridge and Aaron Rinehart’s Security Chaos Engineering, which established the conceptual vocabulary for this kind of work. Casey Rosenthal’s Chaos Engineering provided the foundational principle that chaos experiments educate operators about chaos already inherent in the system. The Chaos Toolkit team’s open-source experiment harness enforces the scientific method that keeps the evolutionary system honest. Thanks to the LocalStack team for IAM enforcement support in their Pro tier — without ENFORCE_IAM=1, the experiments would have been meaningless.
We started with a single S3 probe. Thirty generations and ninety-three cents later, we had a six-step attack chain that three independent lineages converged on. The meta-intelligence correctly diagnosed why the system could not break the final barrier. And the barrier — under all that evolutionary pressure — held.
That last part might be the most important finding of all.


