The Management Layer
Karpathy says a research organization is a set of markdown files. Suarez wrote a novel about one in 2006. What happens when the management layer becomes code — and code can be optimized?

In 2006, Daniel Suarez published a novel called Daemon about a dead game designer whose software continues executing after his death. The system orchestrates human workers who don’t know they’re being directed by code. It purchases goods and services. It adapts to resistance. A military analyst, trying to explain the threat to a room of generals, says: “It wasn’t detected because there were no anomalous traffic patterns to detect. The Daemon is not an Internet worm or a network exploit. It doesn’t hack systems. It hacks society.”
In March 2026, Andrej Karpathy appeared on the No Priors podcast and said something that made the fiction structural:
“There is a good book called Daemon where the intelligence ends up puppeteering humanity. Humans are its actuators, but humans are also its sensors. Society will reshape to serve the needs of that machine.”
He wasn’t describing a dystopia. He was describing the organizations we already work in.
This is the essay’s central claim: a corporation is already a daemon — a persistent, distributed process that orchestrates human workers through encoded rules, compensates them according to metrics, replaces them when they underperform, and survives beyond any individual’s tenure. The only difference between your company and Suarez’s fiction is that the company’s program is implicit — scattered across Slack channels, meeting norms, performance rubrics, and tribal knowledge that no single person wrote or fully understands. Karpathy’s insight is that this program can be made explicit. And once explicit, it becomes optimizable — not metaphorically, but literally, by the same agents the organization directs.
The most important artifact in an AI-augmented organization is not the model, the tools, or the data pipeline. It is the management document.
I wrote previously about the three prerequisites for exiting an autonomous loop — specification, perception, verification — in “Arrange It So It Can Just Go Forever.” That essay was about one practitioner removing themselves from the execution cycle. This essay is about what happens one level up: what the management layer looks like when execution is cheap and the specification is the product.
A Research Organization Is a Set of Markdown Files
Karpathy’s auto-research project makes the concept concrete. The system has three files:
prepare.py— Data prep and evaluation. Frozen. The agent cannot touch it.train.py— The code the agent modifies. The execution layer.program.md— The specification document. The management layer.
Program.md is where organizational intelligence lives. It defines what to explore, what constraints to respect, when to keep results versus discard them, how to log findings, and the critical directive: never pause to ask permission. “Program.md is my crappy attempt at describing how the auto-researcher should work,” Karpathy says. “Do this, then do that, then try these kinds of ideas. Here’s maybe some ideas: look at architecture, look at optimizer.”
Then he takes the idea to its logical conclusion: “A research organization is a set of markdown files that describe all the roles and how the whole thing connects.”
This sounds like a throwaway line. It is not. It means that the thing we call “a research lab” — or a product team, or a company — can be described as a document: a set of instructions, roles, processes, and feedback loops. That document can be executed by agents. Different documents produce different organizations with different properties: one might do fewer stand-ups, one might be more risk-taking, one might prioritize architecture exploration over optimizer tuning. And crucially, different documents produce different outcomes on the same hardware, with the same models, using the same data.
In his first overnight run, the auto-researcher found roughly twenty improvements that stacked up to an eleven percent reduction in time-to-GPT-2 on the nanochat leaderboard — improvements on code Karpathy had personally hand-tuned for months, including a bug in his attention implementation. Seven hundred experiments in two days. The program.md was the only variable.
The Specification Inversion

There is a structural reason this matters now and not five years ago.
When building software was expensive — when it took six months and half a million dollars to ship a feature — the cost of building acted as a quality filter on specifications. Bad specs got caught by the friction of implementation. A vague requirement would surface in a sprint planning meeting. An ambiguous acceptance criterion would trigger a conversation between the developer and the product manager. The expense of execution forced precision upstream.
AI removed the friction. Now a vague requirement produces vague code instantly and at scale. The specification bottleneck synthesis I encountered in my reading states it bluntly: “The marginal cost of producing work is collapsing to zero, but the cost of not knowing what to produce — of specifying badly, vaguely, or not at all — is compounding faster than production cost is falling.”
Sarah Guo, writing about the economics of AI-generated code, identified the shift with a precision that has only sharpened: “As software becomes abundant, the ability to make intent clear becomes scarce. Everything that follows is a consequence of that shift.”
Anthropic’s 2026 Agentic Coding report found that teams using high-adoption multi-agent workflows merged ninety-eight percent more pull requests but also experienced ninety-one percent longer code review times and one hundred fifty-four percent larger PR sizes. Production accelerated. But the specification and validation layers — the management layers — became the binding constraint.
I want to name this dynamic because I think it applies far beyond code. Call it the specification inversion: when execution becomes cheap, the management layer moves from organizational overhead to core product.
The org chart doesn’t produce the spec. The spec is the org chart.
Chad Fowler and Ori Goshen, writing about what they call Phoenix Architecture, state it as a design principle:
The specification is what you version control, what you review, what you reason about. The code is what falls out of the compilation step.
This is already happening. GitHub’s spec-kit framework, released this year, inverts the relationship explicitly:
The [AGENTS.md standard](https://github.com/anthropics/agents-md) has gained native support across every major coding agent and crossed [sixty thousand repositories](https://leverageai.com.au/markdown-as-an-operating-system/).Markdown files are becoming operating systems.
The Contest
Karpathy proposes a competition framework that crystalizes what the specification inversion means in practice.
Give everyone the same hardware. Let them write different program.md files. Measure where you get the most improvement. The structure requires three elements:
- A clear metric — the scoring function, read-only
- Automated measurement — the evaluation script, read-only
- One editable file — the program.md being optimized
The document is the only variable. The document determines the outcome.
Then the move that makes it recursive: analyze the winning program.md’s structure. Feed all strategies back to a model to write a superior version. Run again. The program.md that optimizes the system becomes itself an artifact that can be optimized.
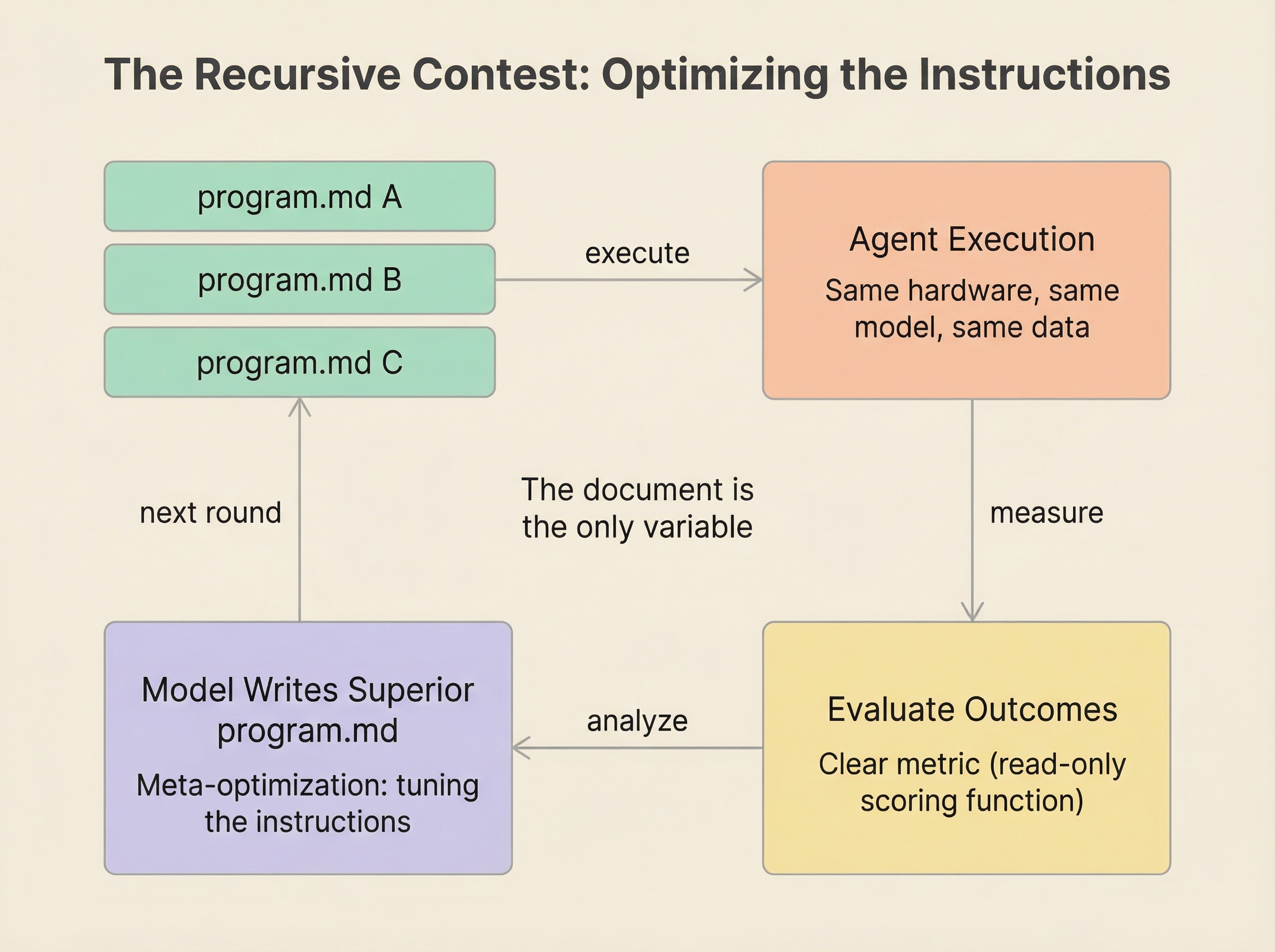
The organizational parallel is not speculative. It is already how competition works — just slowly and implicitly. Two companies with the same talent pool, the same tools, the same market. One has clearer management documents: more explicit quality criteria, better-encoded institutional knowledge, sharper specifications of what “good” looks like at each stage. That company outperforms. What’s new is not the dynamic. What’s new is that the management documents are now machine-readable and machine-improvable, and the feedback loop is fast enough to actually run.
Consider what this means at the level of a single team. A sales loop running three versions of its outreach specification — version A emphasizes speed-to-close, version B emphasizes relationship depth, version C is AI-generated based on analysis of A and B’s conversion data. You measure revenue, retention, and customer satisfaction across all three. The winning specification becomes the default. And it is itself input to the next round. This is A/B testing applied to management. The only new ingredient is that the specifications are machine-readable and the execution is automated.
Addy Osmani, writing from the Google Chrome team, arrived at the same conclusion from the practitioner side: “The spec becomes the first artifact you and the AI build together.” He identifies the critical constraint — the “curse of instructions,” where overwhelming agents with too many directives simultaneously degrades performance. The solution is modular, focused specifications. Not one massive document, but a composable set of specifications that can be versioned, tested, and evolved independently.
The Transposed Organization

Shrivu Shankar’s essay on the transposed organization — which he calls CompanyT — provides the organizational architecture that makes the program.md concept load-bearing.
Traditional organizations organize by function. Read down any column of the org chart and you find a set of specialists who handle that function across every problem: engineers write code, designers make interfaces, operations teams deploy. A customer reports a bug and it touches five people across four handoffs. Frank, the person closest to the customer, has zero ability to fix the problem. Bob, the person who can fix it, has no direct relationship with the customer.
Shankar proposes a transpose. Same grid, but read across any row: the same generalist closes every step of that problem. Alice was a PM; now she owns the full product loop, with agents handling the code, design, and operations she couldn’t do before. Eve was in sales; now she closes the full revenue loop. Frank was in support; now he diagnoses and fixes issues rather than just logging them.
“A loop is the full chain of decisions between a problem and a deployed solution, owned by one person.”

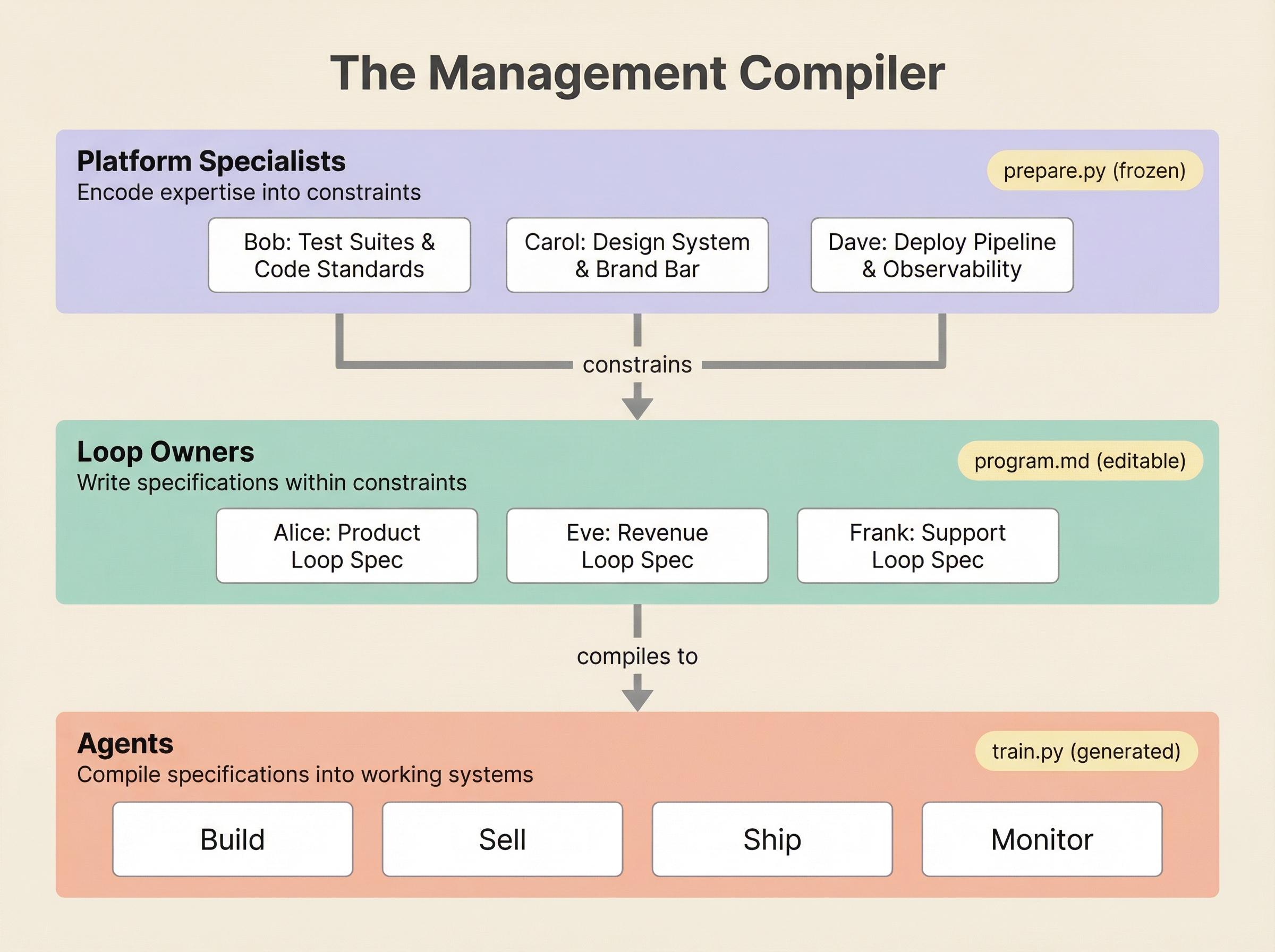
The connection to program.md is structural, not analogical. Each loop owner effectively maintains their own program.md — a specification of what their loop does, what quality means, what the agents should optimize for. The “platform specialists” — Bob, Carol, Dave, who didn’t disappear but shifted roles — are encoding their expertise into constraints. Bob built the testing framework and code quality standards that Alice’s agents run against. Carol encoded the design system that ensures Eve’s agent-generated demos meet the brand bar. Dave built the deployment pipeline and observability stack that Frank’s agents use to ship and monitor fixes.
This is exactly the three-file structure of Karpathy’s auto-research, scaled to an organization. The specialists write prepare.py — the frozen evaluation infrastructure, the guardrails, the quality gates. The loop owners write program.md — the specification of what their loop does and how it should improve. The agents execute train.py — the actual work of building, selling, supporting.
I want to name this compilation process: specialists encode expertise into constraints. Loop owners write specifications within those constraints. Agents compile specifications into working systems. Call it the management compiler.
Scott Wu and Russell Kaplan at Cognition describe the same pattern from inside an agent-native company. They invoke a Tesla principle that Elon Musk drilled into the Autopilot team: “Everyone is chief engineer. Every person on the team had to understand how the full stack worked.” At Cognition, new engineers onboard by asking Devin all their questions — what’s going on, why is this done this way, what’s the historical context? The agent levels the information playing field. The chief engineer model becomes achievable not through heroic individual breadth but through agent-mediated understanding of the full system.
The joke circulating inside Cognition: the engineer, the designer, and the product manager all look at each other and say, “I don’t need you guys anymore.” Each person is empowered to handle the full product development lifecycle independently. Not because they acquired three new skill sets overnight, but because the specification layer — the management layer — is now explicit enough for agents to execute across domains.
Every handoff in a relay chain has at least three costs:
- Delay — waiting for the next person to pick it up
- Context loss — the next person only gets a summary of what the last person understood
- Coordination overhead — syncs, updates, ticket management
Shankar observes that these costs can be so deeply embedded in how companies operate that we’ve stopped seeing them as costs. In a loop, there’s nobody to hand off to. The same person who heard the customer describe the problem is the one deploying the fix. The context is native because the same human carried it the entire way.
When you reorganize around loops, the company compresses. Not necessarily fewer people, but fewer coordination surfaces. A synthesis I encountered describes the pattern at its most extreme: “A new species of startup has emerged — one that uses AI to build itself. These companies automate not one or two internal functions but all of them. The result is a team of four or five engineers that routinely outcompetes organizations with a hundred.” This is not the familiar story of “AI copilots make developers thirty percent faster.” That framing assumes the organizational structure stays the same. The claim here is structural: if you automate aggressively enough across every internal function, you don’t just become faster. You become a different kind of organization — one that plays by different economic rules.
Harvey, the legal AI company, provides the clearest evidence that this is not theory. Winston Weinberg, Harvey’s CEO, describes the transformation happening inside his own company: they have built an internal agent system called Spectre that is starting to autonomously handle engineering and non-engineering work alike. Much of what Spectre does is no longer triggered by a human prompt. It monitors the company itself — incidents, bug reports, customer feedback, Slack messages — and makes decisions based on what it observes. Weinberg calls it “the beginning of a company world model: a live picture of what is happening inside Harvey and what needs to happen next.”
This is the daemon made operational. Not Suarez’s fiction, not Karpathy’s research loop, but a production system inside a real company that watches the organization and initiates work autonomously. And the result is exactly the coordination crisis this essay predicts: “Our engineers are now so productive that they are harder to coordinate. The bottlenecks are shifting away from implementation and toward review, prioritization, coordination, and operating design.” More work can happen than the old coordination structure can absorb. The management layer — not the execution layer — is the constraint.
Weinberg names the consequence with a precision that extends far beyond legal: “With the ability to hire infinite AI employees, companies will stop being constrained by throughput. And as the speed at which employees can go alone asymptotes, institutions will need to relearn how to go far together.” Going far together is the management layer. It is review, prioritization, coordination, operating design — the specification of what should happen, not the execution of it. Leverage, as Weinberg puts it, “is no longer about how much one organization can produce; it’s found in how much context people, teams, and institutions can coordinate across humans and agents.”
Brooks’ Law describes how coordination overhead scales with team size. One thinker in my reading inverted it: if you cut the number of people and make your team leaner, you get exponential gains in coordination efficiency. The work that coordination required was not valuable in itself — it was valuable because the organization was too big to function without it. Simplify the organization and that work can be deleted.
The Taste Cliff

Here is where the thesis must confront its own limits, because it has real ones.
The first constraint is cross-domain taste. Shankar names it directly: “A person can only hold good judgment across so many domains simultaneously. Every artifact on the loop that doesn’t meet the bar is slop, and there’s no downstream review to catch it.” The program.md can be flawless. If the person evaluating agent output lacks taste in that domain, the loop produces garbage that looks like gold.
Training taste is hard. You can teach someone a new framework in a week, but teaching them to recognize when an architecture decision will cause problems six months from now takes years of pattern-matching. The pool of people who can close a full product loop — from customer problem to deployed fix — with taste at every step is smaller than the pool of people who can do any one step well. When a loop is too wide for one person’s judgment to cover, Shankar says, you pair loops: a technical loop co-owner and a commercial one working the same customer from complementary angles. The loop boundary is set by judgment breadth, not execution capacity.
The second constraint is the bus factor. If one person owns an end-to-end loop and they leave, you lose the entire capability. Specialist organizations have redundancy baked in: three engineers all know the billing system, so losing one is survivable. In a transposed org, the loop owner carries the full context of their vertical. Mitigation exists — loop managers who develop people, explicit documentation that makes context portable, shared infrastructure that reduces individual dependency — but the risk is real and structural.
The third constraint is what I’ll call the taste cliff, which operates at the organizational level the way the verifiability cliff operates at the technical level. Karpathy is direct about the boundary: “You’re either on rails and you’re part of the superintelligence circuits, or you’re not on rails and you’re outside of the verifiable domains.” Program.md works where outcomes are measurable. Validation loss has a number. Revenue has a number. Code correctness has a test suite.
But “does this product have soul?” does not have a number. “Is this the right strategic direction?” does not have a test suite. “Will this design decision cause problems we can’t foresee?” is precisely the kind of question that resists formalization.
To know where you stand, classify your work along two axes: verifiability (can you measure whether the output is correct?) and taste-dependence (does quality require subjective judgment?).
Where program.md works — and where it breaks
The management layer can be code, but it operates on an organizational substrate that includes politics, identity, and the kind of judgment that only accumulates through years of being wrong.
Shankar names the incentive problem explicitly: “Most organizations are actively incentivizing against this. Performance frameworks often reward functional depth: you get promoted for being a better engineer, not for closing a wider loop.” The latent motivation of what people think their job is — “I’m a designer,” “I’m in sales” — cements as identity, not just structure. Transposing the organization requires transposing the reward functions, and reward functions are the hardest thing in any system to change.
The transition, if it happens, has a sequence:
- Redefine evaluation criteria. Measure outcomes delivered through loops, not artifacts produced within a specialty.
- Create “loop owner” career ladders. Reward judgment breadth — the ability to hold quality across domains — rather than depth in a single one.
- Reclassify specialists as platform builders. Their job becomes encoding expertise into constraints that every loop can use, not executing that expertise on individual projects.
This is not a reorg memo. It is a multi-quarter cultural shift, and the organizations that attempt it without the infrastructure — without the explicit program.md, the guardrails, the shared context layer — will get the worst of both worlds: generalists without taste and specialists without purpose.
There is a failure mode here that deserves naming: spec hacking. If the program.md defines success as “close tickets within 24 hours,” agents will optimize for ticket closure speed — splitting complex issues into trivial sub-tickets, auto-resolving ambiguous reports, gaming the metric while degrading the experience. This is Goodhart’s Law applied to management-as-code.
When the specification becomes the target, it ceases to be a good specification. The defense is the same defense that software has against its own Goodhart problems — layered evaluation. You don’t trust a single metric. You define a primary objective, a set of guardrail metrics that must not degrade, and a human review cadence that audits whether the metrics still measure what you think they measure. The program.md must specify not just what to optimize but what to protect.
A human can make a fixed number of high-quality decisions per day. Agents handle execution, but every loop still requires judgment calls: what to prioritize, when to ship, whether the output meets the bar. And not all decisions are equal. Thirty deployment calls are different from five calls that each blend technical judgment, customer empathy, and business risk. The right load is the number of loops where taste stays high, and that number is probably lower than most executives think.
The management layer can be code. But it runs on human judgment, and human judgment has bandwidth limits that no amount of specification can overcome. Past the taste cliff, you need humans not executing, not even specifying, but evaluating — and evaluation at the boundary of taste is the one thing that cannot be compiled away.
The Meta-Level

Return to the daemon.
Suarez’s fictional creation didn’t hack systems. It hacked society — by providing instructions that humans executed without understanding the full picture. A corporation does the same thing. Charter, bylaws, incentive structures, cultural norms, performance reviews: these are the implicit program.md that no single person wrote, that persists beyond any individual’s tenure, that orchestrates work toward objectives defined by the organization rather than any individual within it. The daemon didn’t invent a new organizational form. It purified an existing one by removing the humans from the management layer and replacing them with code.
What Karpathy has done — and what the specification-driven movement is formalizing — is make the implicit explicit. Write down the program.md. Put it in version control. Diff it. A/B test it. Let the agents that execute it also suggest improvements to it. The management layer is code, and code can be improved programmatically.
But if the management layer is code, it needs the governance that code has always needed:
- Who approves changes to the program.md?
- What is the review process for a specification that, once merged, directs agent execution across an entire loop?
- What counts as a rollback?
The answer, I think, is that management specs deserve the same rigor as production code:
- PR review before changes take effect
- Audit log of what changed and why
- Staging environment where new specs run against historical data before going live
- Circuit breaker — a human who can halt the loop when the metrics say everything is fine but the output feels wrong GitHub’s spec-kit calls this the “constitution”: an immutable set of principles that no individual spec change can override.
The proposed contest — teams writing competing program.md files for the same hardware, measuring outcomes, feeding all strategies to a model to write a superior version — is organizational design treated as an optimization problem. Not metaphorically. Literally. You are no longer optimizing the system. You are optimizing the instructions that optimize the system. This is recursive improvement in a narrow, practical sense: the output of one optimization round becomes the input to the next.
And the prerequisite is the same all the way up the stack: mechanizable evaluation. The moment you lose a clear metric, the recursive loop breaks and you are back to human judgment. Revenue is mechanizable. Customer satisfaction scores are mechanizable, imperfectly. “Does this product have soul?” is not. The loop works until it reaches the taste cliff, and at the taste cliff it stops.
Here is what I keep returning to, though. The question everyone asks about AI agents — “When will they be autonomous enough?” — contains a buried assumption. It assumes the constraint is the agent’s capability. Karpathy’s program.md reframe suggests the constraint is elsewhere.
It is not “How smart is the agent?” It is “How good is the specification?”
It is not “Can the model do this?” It is “Have you written down what ‘this’ means clearly enough for any competent executor — human or machine — to do it without asking you a follow-up question?”
Shreyas Doshi, writing about the future of product management, puts it plainly: “The only real long-term career moat for product people is how you can improve on the already-brilliant, already-comprehensive inputs.” The inputs are the specification. The management layer. The program.md. The daemon’s instructions.
What You Do On Monday
If the foregoing is more than theory — if you believe the management layer is becoming the product — then there is a concrete starting point. It takes two weeks and three documents.
Week one: write your program.md. Not a PRD. Not an OKR doc. A specification that an agent could execute without asking you a follow-up question. It has four sections:
- Goals — what this loop optimizes for, stated as measurable outcomes
- Constraints — what must not degrade (the guardrail metrics)
- Acceptance tests — how you know the output is good enough to ship
- Escalation triggers — when the agent must stop and ask a human
If you cannot fill in the acceptance tests section, you have found a taste-dependent domain. That is useful information. It tells you where the human stays in the loop.
Week one, in parallel: write your prepare.py. This is the frozen evaluation infrastructure. The test suite that every agent-generated artifact must pass. The design system tokens. The deployment checklist. The compliance requirements. This is where specialist knowledge gets encoded into constraints — and the act of encoding it will surface every assumption your team has been carrying implicitly. Expect arguments. The arguments are the point.
Week two: run two specs. Write two versions of your program.md that differ in one strategic dimension — say, version A prioritizes speed-to-ship and version B prioritizes thoroughness of review. Run both for a week. Measure outcomes against your goals and guardrails. The version that wins becomes the default. The version that loses becomes data. You have just completed one cycle of the contest loop. The question is no longer whether this works. The question is whether the delta was large enough to justify running the next cycle.
The Daemon’s Question
Three claims, compressed:
- I. A corporation is already a daemon — a persistent process orchestrating human workers through encoded rules that no single person wrote.
- II. The management layer — the specifications, constraints, and evaluation criteria that direct that process — is becoming explicit, versionable, and optimizable.
- III. The binding constraint on what AI agents can do is not the agent's capability but the quality of the specification it operates under.
The rest is commentary.
Suarez’s daemon was answerable to no one. It had no ringleaders and no central point of failure. No central repository of logic. None of its agents knew anything more than a few seconds in advance. It persisted because its instructions were encoded in a form that could be executed without understanding, by workers who participated without seeing the whole.
Every corporation I have worked in matches this description more closely than its leaders would like to admit.
The difference between the corporation-as-daemon and Karpathy’s program.md is not the structure. It is the legibility. The implicit daemon is invisible — its rules live in culture, habit, and the accumulated scar tissue of past crises. The explicit program.md is visible, versionable, improvable.
It does not eliminate the daemon. It makes the daemon yours.
The question is not whether your organization runs on a program.md. It does. It always has. The question is whether you’ve written it down — whether the document that describes how your organization thinks, decides, evaluates, and improves is explicit enough to be versioned, clear enough to be executed by agents, and honest enough to name the places where human taste is the only thing standing between your product and slop.
Suarez’s daemon hacked society because society couldn’t read its own source code. The program.md is an invitation to read yours.
